3DCodeBench: Benchmarking
Agentic Procedural 3D Modeling Via Code
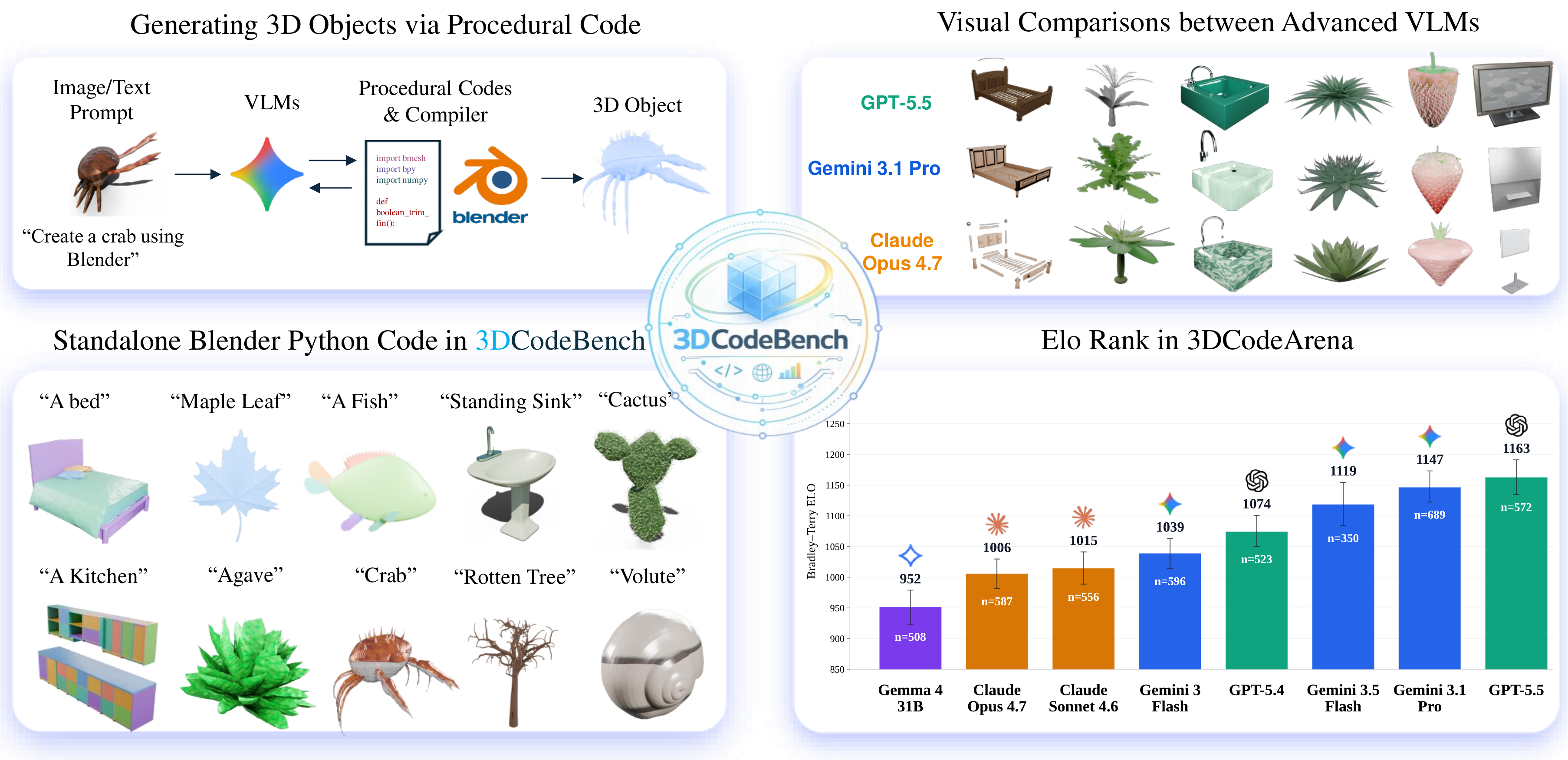
Overview of 3DCodeBench: 212 procedural object classes, 12 frontier VLMs evaluated under multi-turn agentic refinement, plus a public 3DCodeArena for human-preference Elo rankings.
Agentic data curation pipeline
A VLM-driven agent transforms deeply nested procedural factories from Infinigen into standalone Blender Python scripts via API migration, geometric validation, and iterative visual refinement. Every generated (prompt, code, mesh) triplet passes a human-in-the-loop verification gate to guarantee benchmark quality.
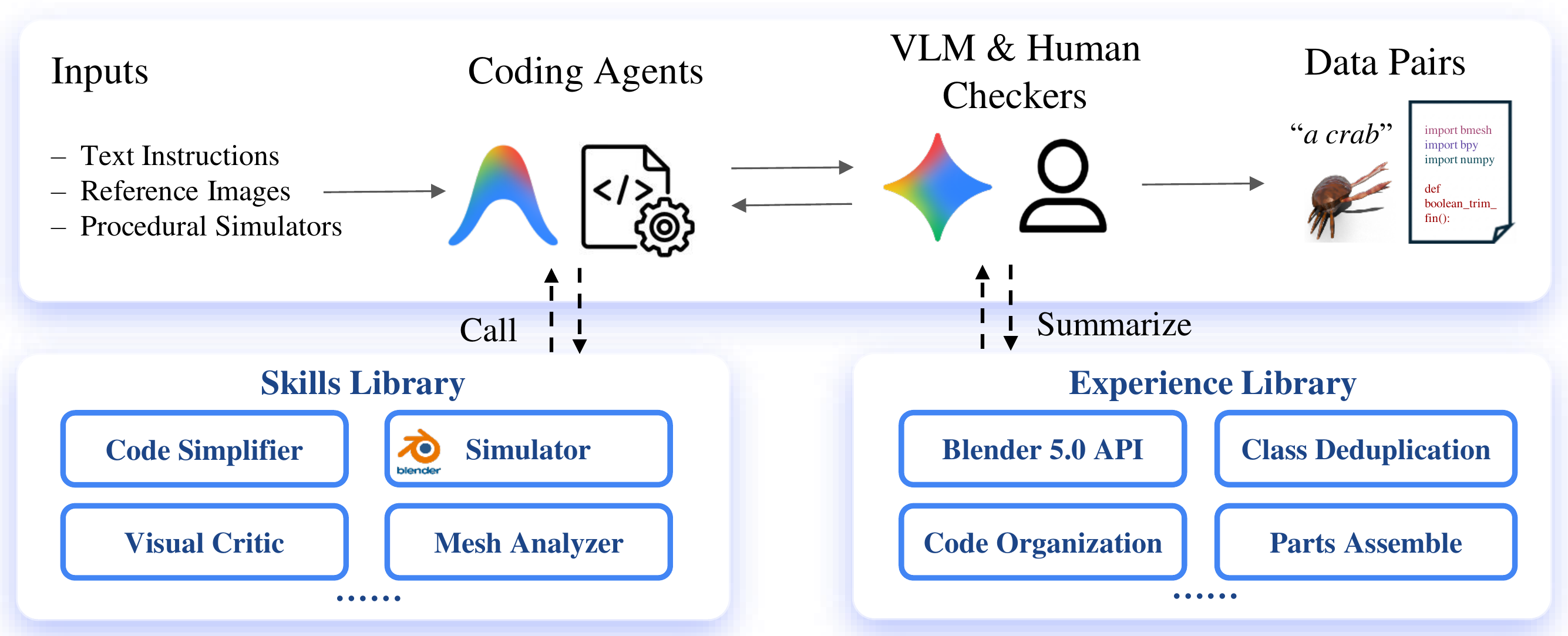
Execution feedback — every successful API migration, fix, or refactor becomes a reusable skill the agent retrieves on later factories.
Established solutions to recurring patterns (custom nodegroups, displacement, particle systems) are indexed and surfaced when the agent encounters a similar factory shape.
Each (prompt, code, mesh) triplet is reviewed by a human annotator. Failed or visually drifted outputs are rejected and re-queued for the agent loop.
At a Glance
Physical Plausibility supersedes Executability. Models frequently produce disconnected parts and misaligned structures, revealing a critical lack of physical-world understanding.
Test-Time Scaling helps. Multi-turn refinement with deterministic Blender feedback improves performance — the agentic harness matters as much as the model.
Open data for training and evaluation. 3DCodeData ships 12,720 factory instances (212 categories × 60 seeds) with per-instance Blender code, multi-view renders, baked GLBs, and LLM-generated captions — ready for SFT, instruction tuning, and shape scoring.
Examples
3DCodeData reference and model outputs side by side, shown with original materials. Drag to rotate · scroll to zoom.
Chameleon
ChameleonTip: use ← / → keys to step through examples.
Results
Quantitative results from the 3DCodeBench paper. Click any column header in the main table to sort; ablation tabs swap the metric being plotted.
Cost vs. Human-Preference Elo
Live BT-Elo from 3DCodeArena against per-query list price across paid frontier VLMs. Dashed line traces the Pareto frontier.
Human-preference Elo vs. automated metrics
Each panel plots 3DCodeArena BT-Elo against one automated metric. Toggle between the text-to-3D, image-to-3D, and combined tracks; hover a point to see the model. Chamfer uses a reversed x-axis so every panel reads left-to-right as “better metric → higher Elo”.
Main results — single-shot
212 categories, one model call per instance (no agent, retry, or tool use). Toggle Text → 3D / Image → 3D above the table; click any column to sort. Exec. is the Blender 5.0 pass rate. Image-grounded compares rendered vs. reference views. 3D-shape compares the exported GLBs. Cost is mean per-query list price.
| Model | Exec.↑↕ | SigLIP-2↑↕ | DINOv3↑↕ | Chamfer↓↕ | Uni3D↑↕ | Uni3D t/i–3D↑↕ | Elo↑▼ | Tokens↕ | Time (s)↕ | Tok/s↕ | Cost $↕ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-5.5 | 0.873 | 0.827 | 0.551 | 0.066 | 0.527 | 0.263 | 1167 | 3,281 | 161.1 | 20 | $0.25 |
| Gemini 3.1 Pro | 0.693 | 0.823 | 0.540 | 0.079 | 0.518 | 0.251 | 1149 | 2,245 | 123.0 | 18 | $0.16 |
| Gemini 3.5 Flash | 0.410 | 0.828 | 0.548 | 0.071 | 0.571 | 0.276 | 1112 | 3,811 | 80.6 | 47 | $0.05 |
| GPT-5.4 | 0.863 | 0.815 | 0.541 | 0.071 | 0.524 | 0.264 | 1074 | 2,652 | 167.6 | 16 | $0.17 |
| Gemini 3 Flash | 0.608 | 0.818 | 0.511 | 0.071 | 0.497 | 0.252 | 1034 | 2,065 | 30.7 | 67 | $0.02 |
| Claude Sonnet 4.6 | 0.792 | 0.821 | 0.545 | 0.071 | 0.505 | 0.256 | 1022 | 19,494 | 239.4 | 81 | $0.30 |
| Claude Opus 4.7 | 0.881 | 0.817 | 0.555 | 0.067 | 0.514 | 0.273 | 1008 | 4,778 | 57.1 | 84 | $0.14 |
| GPT-5.4 mini | 0.590 | 0.798 | 0.511 | 0.121 | 0.418 | 0.228 | 950 | 24,530 | 151.4 | 162 | $0.11 |
| Gemma 4 31B | 0.582 | 0.798 | 0.518 | 0.076 | 0.494 | 0.262 | 946 | 4,288 | 121.6 | 35 | — |
| Gemini 3.1 Flash Lite | 0.599 | 0.781 | 0.481 | 0.075 | 0.445 | 0.248 | 880 | 8,927 | 40.9 | 218 | $0.01 |
| Gemma 4 26B | 0.517 | 0.780 | 0.483 | 0.078 | 0.436 | 0.249 | 860 | 6,126 | 132.7 | 46 | — |
| Claude Haiku 4.5 | 0.511 | 0.763 | 0.415 | 0.083 | 0.365 | 0.223 | 798 | 5,248 | 30.7 | 171 | $0.03 |
| Claude Opus 4.8 | 0.868 | 0.776 | 0.516 | 0.065 | 0.534 | 0.267 | — | 6,124 | 75.9 | 81 | $0.20 |
| Fable 5 | 0.920 | 0.771 | 0.538 | 0.061 | 0.558 | 0.279 | — | 8,035 | 100.4 | 80 | $0.56 |
Main results — coding agent
The same 212 categories, but each model runs inside an autonomous coding-agent harness (Claude Code / Codex / Gemini CLI / Antigravity) that executes Blender, reads the errors, and retries. Same metrics and convention as above, with the same Text / Image toggle. Agents reach near-perfect executability, so the contest shifts to image- and 3D-shape fidelity. Fable 5 · Claude Code leads on shape; GPT-5.5 · Codex on image similarity.
| Model | Exec.↑↕ | SigLIP-2↑▼ | DINOv3↑↕ | Chamfer↓↕ | Uni3D↑↕ | Uni3D t/i–3D↑↕ | Tokens↕ | Time (s)↕ | Tok/s↕ | Cost $↕ |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-5.5 · Codex | 0.995 | 0.816 | 0.544 | 0.062 | 0.519 | 0.267 | 6,200 | 97.0 | 64 | $0.30 |
| Fable 5 · Claude Code | 1.000 | 0.799 | 0.557 | 0.061 | 0.564 | 0.278 | 5,241 | 75.1 | 70 | $0.68 |
| Claude Opus 4.8 · Claude Code | 1.000 | 0.799 | 0.538 | 0.062 | 0.529 | 0.270 | 5,643 | 71.2 | 79 | $0.33 |
| Claude Opus 4.7 · Claude Code | 1.000 | 0.798 | 0.530 | 0.068 | 0.524 | 0.264 | 4,051 | 55.4 | 73 | $0.17 |
| Gemini 3.1 Pro · Gemini CLI | 0.991 | 0.795 | 0.515 | 0.073 | 0.507 | 0.260 | 3,392 | 227.8 | 15 | $0.37 |
| Gemini 3 Flash · Gemini CLI | 0.995 | 0.788 | 0.505 | 0.073 | 0.501 | 0.249 | 5,944 | 99.3 | 60 | $0.12 |
| Gemini 3.5 Flash · Antigravity | 0.986 | 0.787 | 0.518 | 0.071 | 0.519 | 0.261 | — | 79.1 | — | — |
| GPT-5.4 · Codex | 1.000 | 0.786 | 0.506 | 0.067 | 0.496 | 0.264 | 13,668 | 230.1 | 59 | $0.31 |
| Claude Sonnet 4.6 · Claude Code | 0.986 | 0.783 | 0.506 | 0.062 | 0.514 | 0.262 | 5,279 | 75.7 | 70 | $0.12 |
| GPT-5.4 mini · Codex | 1.000 | 0.768 | 0.463 | 0.072 | 0.444 | 0.244 | 9,401 | 75.7 | 124 | $0.06 |
| Claude Haiku 4.5 · Claude Code | 0.986 | 0.738 | 0.401 | 0.079 | 0.385 | 0.213 | 13,135 | 84.9 | 155 | $0.12 |
| Gemini 3.1 Flash Lite · Gemini CLI | 1.000 | 0.725 | 0.386 | 0.089 | 0.371 | 0.205 | 2,096 | 37.1 | 57 | $0.04 |
Ablations
Test-time scaling lifts executability dramatically; coding-agent harnesses push every backbone to near-ceiling; multi-view input budgets show diminishing returns past N=2 on cheaper models.
Multi-turn error feedback
T=3 retry loop on the failed instances. Switch metric →
Pass rate before and after the multi-turn loop. Up to two stateless retries that consume the previous code and Blender traceback.
Coding-agent harness
Each backbone wrapped in its native coding-agent harness (Gemini CLI / Claude Code / Codex CLI / Antigravity CLI) on the text-to-3D track. Switch metric →
Executability: fraction of prompts that produce a non-empty mesh in Blender 5.0. Bigger bar = more successful runs.
Multi-view input budget
How does giving the model more reference views (N) affect output quality? Each line is one backbone, mean across 3 seeds at thinking=high.
Appendix
Click a row to expand the full breakdown. All numbers come from the appendix tables in the paper.
Contribute
3DCodeBench is open. The benchmark grows by adding new categories — chairs, plants, hardware, vehicles, anything we don’t cover yet. Each category is just three text files; the workflow is friendly to a single PR.
A self-contained Blender 5.0 Python script that builds your object. No external imports, deterministic at seed=0, under 5 minutes on one CPU core.
prompt_description.txt— a one-paragraph caption a human could visualise. prompt_instruction.txt — a structured spec covering parts, proportions, and finish.
Drop the three files into benchmark/categories/<Name>_seed0/, include a 200×200 render and one line of motivation, and submit.
New eval tasks (e.g. sketch-to-3D) and metrics(e.g. material-fidelity scorer) are also welcome — please open an issue first to align on scope.
Cite
@article{gao20263dcodebench,
title={3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code},
author={Gao, Yipeng and Shu, Lei and Ye, Genzhi and Xiong, Xi and Makadia, Ameesh and Guo, Meiqi and Itti, Laurent and Chen, Jindong},
journal={arXiv preprint arXiv:2606.01057},
year={2026}
}BibTeX coming soon — arXiv link pending.